【スクレイピングでキーワード選定効率化】検索ボリューム・競合調査結果を一括出力【Python】

SEO対策の1つであるキーワード選定をスクレイピングで効率化できないかと思い、やってみたところ意外と簡単にできたのでその手法を公開します。
前提
上位表示を狙うためにボリュームの大きさを調べたり競合サイト数のリサーチを行うと思います。
例えば、○○の特化サイトの場合、検索のボリュームの大きい「○○ △△ ××」というキーワードで実際に検索し、上位に競合が多く出ないか(裏返すと「コンテンツ内容が薄いサイトが上位に出現するか」)を調べます。
今回はその過程を効率化する方法について紹介します。
【上位表示を狙いやすいキーワードの特徴】
- 検索ボリューム(月間検索数)が大きい
- 競合が少ない
これをプログラムに落とし込みます
できること
指定した文字列を含むURLのサイトが上位に表示される際のキーワード、検索ボリューム、そのサイトの順位、タイトル、URLをスプレッドシートに出力

下準備
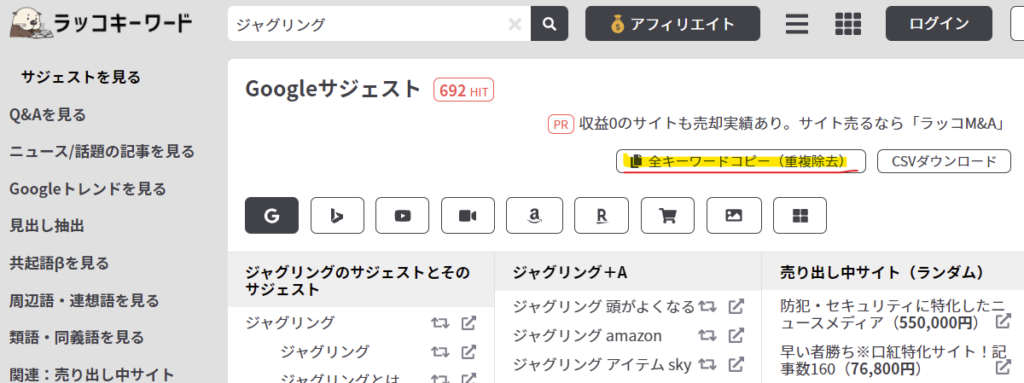
ラッコキーワードから候補をコピー
ラッコキーワードでメインのキーワードを入力し検索

検索結果画面右上の全キーワードコピーをクリック
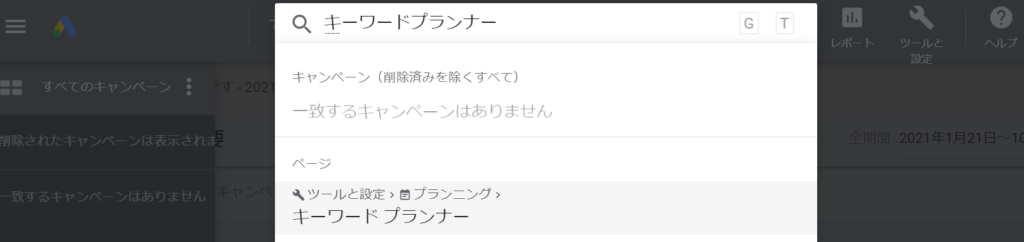
キーワードプランナーで検索ボリュームを取得
Google広告を開き検索窓にキーワードプランナーと入力し選択(この辺りはUIが変わりやすいので手順は参考程度に…)
(※未登録の場合はアカウント作成からです。Gmailアドレスが必要。)
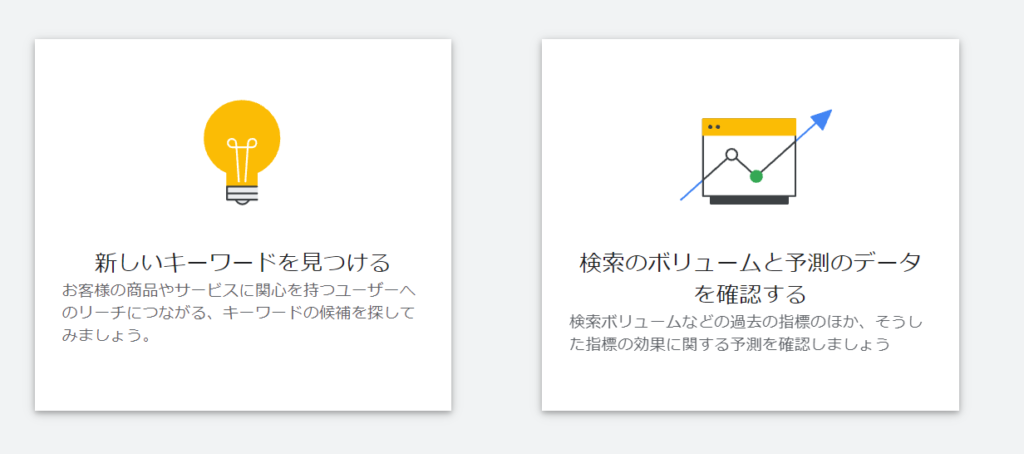
キーワードプランナーの開始画面で「検索のボリュームと予測データを確認する」を選択
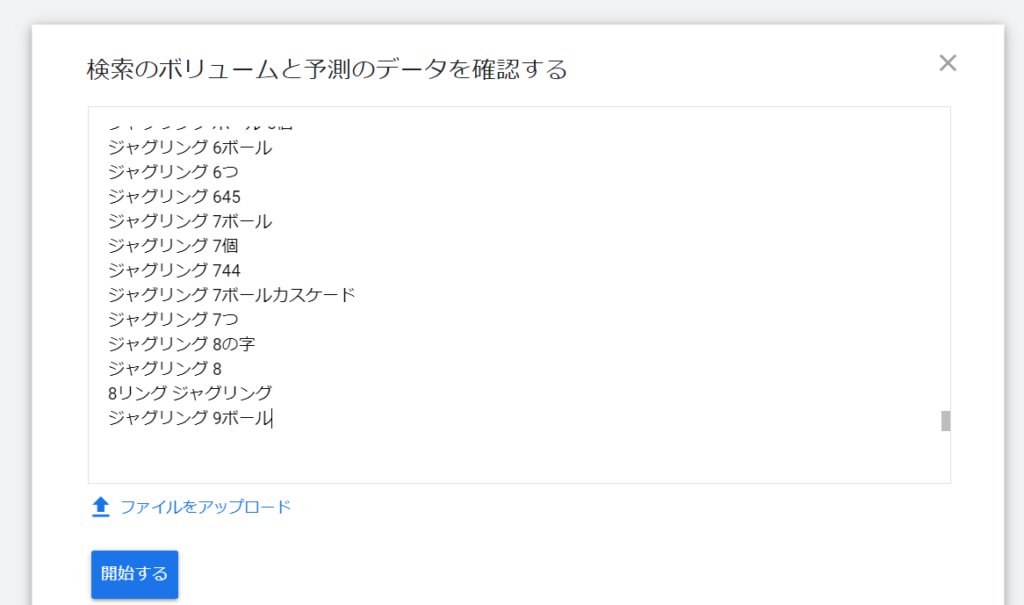
先ほどコピーしたキーワードを張り付けて「開始する」をクリック
右上のダウンロードのマーク「⇩」をクリック
過去のプラン指標の「Googleスプレッドシート」を選択
ファイル名とフォルダを指定してダウンロードボタンをクリック
「スプレッドシートを開く」をクリックするとスプレッドシートが開く

シート名を変更
入力用シートの名前を”in”、出力用を”out”としておく。
スクレイピング
Google Colaboratoryを開いて新しいノートブックを作成し下記コードを貼り付け
import requests
from bs4 import BeautifulSoup
from time import sleep
from google.colab import auth
from google.auth import default
import gspread
# シート読み込み
auth.authenticate_user()
creds, _ = default()
gc = gspread.authorize(creds)
ss_url = 'ここにスプレッドシートのURLを記載してください'
workbook = gc.open_by_url(ss_url)
sheet_in = workbook.worksheet("in")
sheet_out = workbook.worksheet("out")
# 行範囲を指定
start = 6
end = 100
# 抽出用URLを指定
target_url = 'https://detail.chiebukuro.yahoo.co.jp/'
for i in range(start, end + 1):
# Google検索するキーワードを設定
search_word = sheet_in.cell(i,1).value
# キーワードのボリューム
if(sheet_in.cell(i,4).value != ""):
volume = int(float(sheet_in.cell(i,4).value))
else:
volume = 0
# 検索順位10位まで調べる
rank_max = 10
pages_num = rank_max + 1
print(f'{i} {search_word}')
# ヘッダー出力
if(sheet_out.cell(1,1).value == ""):
sheet_out.append_row(["キーワード", "ボリューム", "順位", "タイトル", "URL"])
# Googleから検索結果ページを取得
url = f'https://www.google.co.jp/search?hl=ja&num={pages_num}&q={search_word}'
request = requests.get(url)
# Googleのページ解析
soup = BeautifulSoup(request.text, "html.parser")
search_site_list = soup.select('div.kCrYT > a')
# ページ解析,結果出力
for rank, site in zip(range(1, pages_num), search_site_list):
try:
site_title = site.select('h3.zBAuLc')[0].text
except IndexError:
site_title = "取得できませんでした"
site_url = site['href'].replace('/url?q=', '').split('&sa=U')
# 結果出力(条件:指定URLが含まれる かつ ボリューム≧50)
if((target_url in site_url[0]) and ( volume >= 50 )):
# スプレッドシートに出力
sheet_out.append_row([search_word, volume, rank, site_title, site_url[0]])
# 20秒待機
sleep(20)
※最初の方にあるss_url = 'ここにスプレッドシートのURLを記載してください'の部分は保存したスプレッドシートのURLに書き換えてください。
※行範囲はスプレッドシートのキーワードが入っている行の番号を指定してください。
※抽出用URLに抽出したいサイトのURLを指定してください。(お悩み相談系のサイトが上位表示されることを条件とすることで「コンテンツの充実した競合サイトが少ない」キーワードを探し出すことができます。)
【お悩み相談系サイト】
- Yahoo!知恵袋:
https://detail.chiebukuro.yahoo.co.jp/ - 教えて!goo:
https://oshiete.goo.ne.jp/ - OKWAVE(オウケイウェイヴ):
https://okwave.jp/ - teratail(テラテイル):
https://teratail.com/
※待機時間も問題無いよう設定していますが実行は自己責任でお願いします。スクレイピングのルールがまとまっている記事も参考にどうぞ)
実行ボタン(▶)をクリックすると認証を求められるのでURLリンクをクリックして認証する。
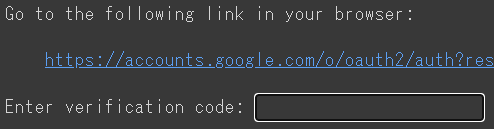

ログイン後、認証コードをコピーしEnter verification code:の欄に入力しEnterを押すと実行される
スプレッドシートの”out”シートに条件に合ったキーワードが抽出されていく

最後に
今回のようなスクレイピングはUdemyで勉強するだけでも簡単に習得できるのでおすすめです。
PythonによるWebスクレイピング〜入門編〜【業務効率化への第一歩】
Pythonによるビジネスに役立つWebスクレイピング(BeautifulSoup、Selenium、Requests)
スクレイピングで効率的にデータを収集・活用する技術を身に付けておくことで、思いついたときに自力で(ググりまくるが)業務を効率化できます。
参考サイト


※2022/07/18訂正内容:
from oauth2client.client import GoogleCredentialsをfrom google.auth import defaultに変更
gc = gspread.authorize(GoogleCredentials.get_application_default())をcreds, _ = default()
gc = gspread.authorize(creds)
に変更しました。